概述
User Space Drivers in Linux
uio
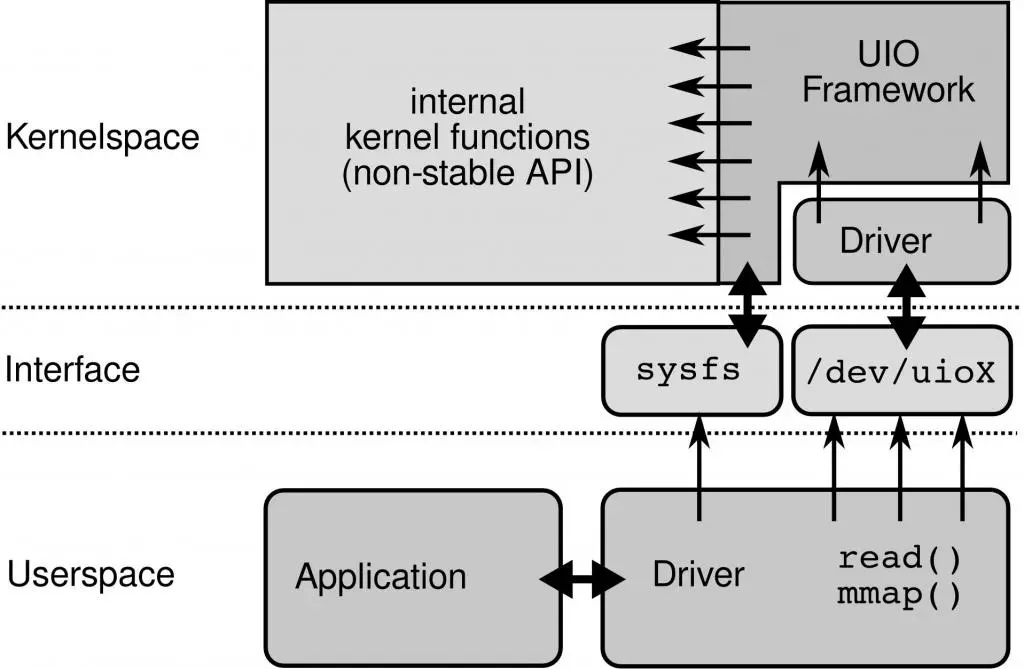
-
uio exposes
all necessary interfacesto write full user space
drivers viamemory mapping filesin thesysfspseudo filesystem. -
These file-based APIs give us full access to the device
without needing to write any kernel code.
vfio
-
vfio offers more features:
IOMMUandinterruptsare only
supported with vfio -
these features come at the
cost of additional complexity: It requiresbinding the PCIe
device to the genericvfio-pci driverand it then exposes
an API viaioctl syscallson special files.
VFIO是一个可以安全地把设备I/O、中断、DMA等暴露到用户空间(userspace),从而可以在用户空间完成设备驱动的框架。用户空间直接设备访问,虚拟机设备分配可以获得更高的IO性能。依赖于IOMMU. vfio-pci.相比于UIO,VFIO更为强健和安全
- The driver can initiate an access to the device’s
Base Address Registers (BARs)or the device can initiate adirect memory access (DMA)to access arbitrary main memory locations.- BARs are used by the device to expose configuration
and control registers to the drivers.- These registers are available
either via memory mapped IO (MMIO) or via x86 IO
ports depending on the device, the latter way of exposing
them is deprecated in PCIe.
案例说明
用户态的网卡驱动设备
DPDK

DPDK架构
左边是原来的方式数据从 网卡 -> 驱动 -> 协议栈 -> Socket接口 -> 业务
右边是DPDK的方式,基于UIO(Userspace I/O)旁路数据。数据从 网卡 -> DPDK轮询模式-> DPDK基础库 -> 业务
用户态的好处是易用开发和维护,灵活性好。并且Crash也不影响内核运行,鲁棒性强。
DPDK支持的CPU体系架构:x86、ARM、PowerPC(PPC)
DPDK支持的网卡列表:click here,我们主流使用Intel 82599(光口)、Intel x540(电口)
DPDK 核心设计
-
用户态驱动程序,基于
UIO- UIO旁路了内核,主动轮询去掉硬中断,DPDK从而可以在用户态做收发包处理。带来Zero Copy、无系统调用的好处,同步处理减少上下文切换带来的Cache Miss。
-
PMD(Poll Mode Driver)DPDK的UIO驱动屏蔽了硬件发出中断,然后在用户态采用主动轮询的方式.-
运行在PMD的Core会处于用户态CPU100%的状态.网络空闲时CPU长期空转,会带来能耗问题。所以,DPDK推出Interrupt DPDK模式。
-
它的原理和NAPI很像,就是没包可处理时进入睡眠,改为中断通知。并且可以和其他进程共享同个CPU Core,但是DPDK进程会有更高调度优先级。
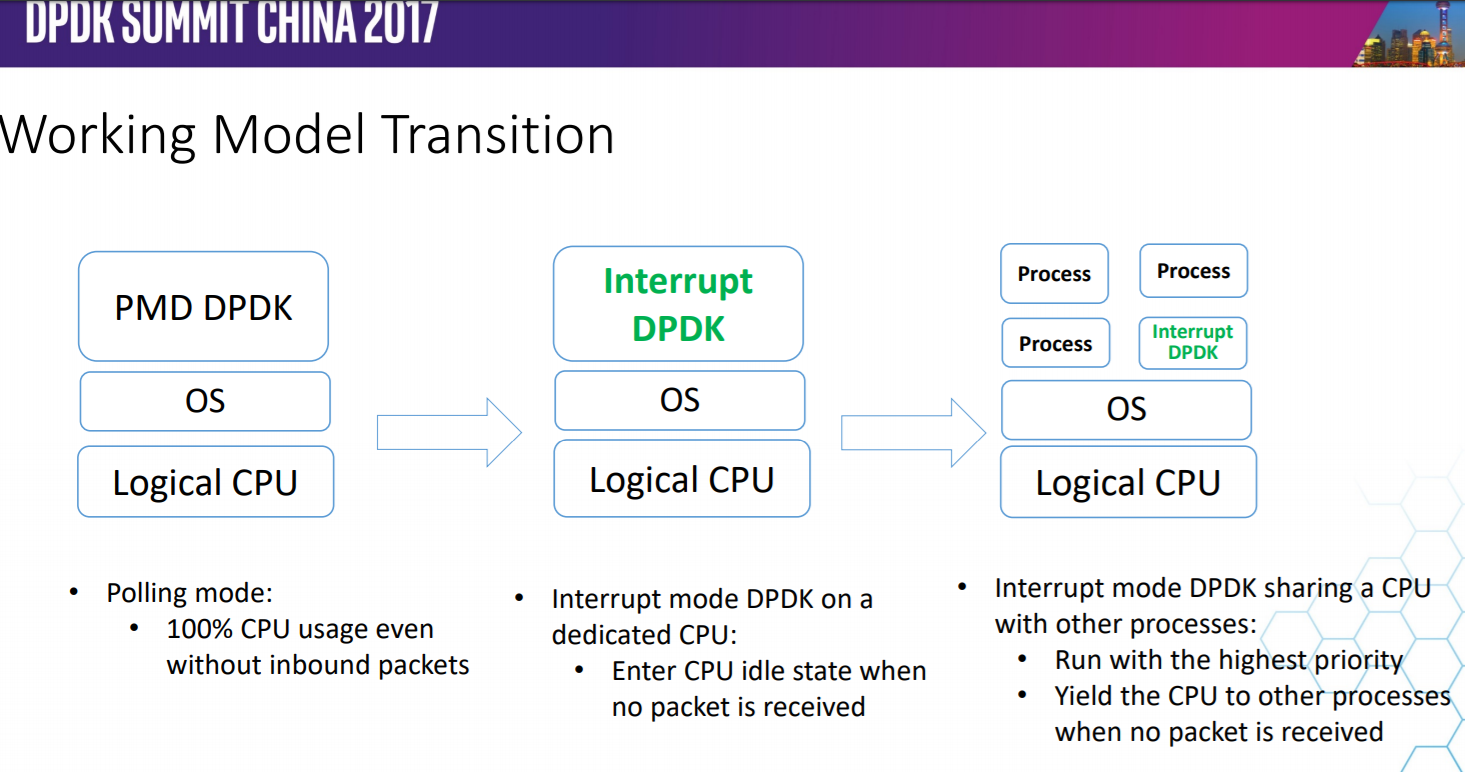
-
DPDK性能优化
-
采用HugePage减少TLB Miss
默认下Linux采用4KB为一页,页越小内存越大,页表的开销越大,页表的内存占用也越大。CPU有TLB(Translation Lookaside Buffer)成本高所以一般就只能存放几百到上千个页表项。如果进程要使用64G内存,则64G/4KB=16000000(一千六百万)页,每页在页表项中占用16000000 * 4B=62MB。
如果用HugePage采用2MB作为一页,只需64G/2MB=2000,数量不在同个级别。而DPDK采用HugePage,在x86-64下支持2MB、1GB的页大小,几何级的降低了页表项的大小,从而减少TLB-Miss。并提供了内存池(Mempool)、MBuf、无锁环(Ring)、Bitmap等基础库。根据我们的实践,在数据平面(Data Plane)频繁的内存分配释放,必须使用内存池,不能直接使用rte_malloc,DPDK的内存分配实现非常简陋,不如ptmalloc。
-
SNA(Shared-nothing Architecture)
软件架构去中心化,尽量避免全局共享,带来全局竞争,失去横向扩展的能力。NUMA体系下不跨Node远程使用内存。
-
SIMD(Single Instruction Multiple Data)
从最早的mmx/sse到最新的avx2,SIMD的能力一直在增强。DPDK采用批量同时处理多个包,再用向量编程,一个周期内对所有包进行处理。比如,memcpy就使用SIMD来提高速度。
SIMD在游戏后台比较常见,但是其他业务如果有类似批量处理的场景,要提高性能,也可看看能否满足。
-
不使用慢速API
这里需要重新定义一下慢速API,比如说gettimeofday,虽然在64位下通过vDSO已经不需要陷入内核态,只是一个纯内存访问,每秒也能达到几千万的级别。但是,不要忘记了我们在10GE下,每秒的处理能力就要达到几千万。所以即使是gettimeofday也属于慢速API。DPDK提供Cycles接口,例如rte_get_tsc_cycles接口,基于HPET或TSC实现。
在x86-64下使用RDTSC指令,直接从寄存器读取,需要输入2个参数,比较常见的实现:
1 | static inline uint64_t |
这么写逻辑没错,但是还不够极致,还涉及到2次位运算才能得到结果,我们看看DPDK是怎么实现:
1 | static inline uint64_t |
巧妙的利用C的union共享内存,直接赋值,减少了不必要的运算。但是使用tsc有些问题需要面对和解决
-
CPU亲和性,解决多核跳动不精确的问题
-
内存屏障,解决乱序执行不精确的问题
-
禁止降频和禁止Intel Turbo Boost,固定CPU频率,解决频率变化带来的失准问题
- 编译执行优化
- 分支预测
现代CPU通过pipeline、superscalar提高并行处理能力,为了进一步发挥并行能力会做分支预测,提升CPU的并行能力。遇到分支时判断可能进入哪个分支,提前处理该分支的代码,预先做指令读取编码读取寄存器等,预测失败则预处理全部丢弃。我们开发业务有时候会非常清楚这个分支是true还是false,那就可以通过人工干预生成更紧凑的代码提示CPU分支预测成功率。
1 |
- CPU Cache预取
Cache Miss的代价非常高,回内存读需要65纳秒,可以将即将访问的数据主动推送的CPU Cache进行优化。比较典型的场景是链表的遍历,链表的下一节点都是随机内存地址,所以CPU肯定是无法自动预加载的。但是我们在处理本节点时,可以通过CPU指令将下一个节点推送到Cache里。
1 |
|
- 内存对齐
内存对齐有2个好处:
l 避免结构体成员跨Cache Line,需2次读取才能合并到寄存器中,降低性能。结构体成员需从大到小排序和以及强制对齐。参考《Data alignment: Straighten up and fly right》
1 |
多线程场景下写产生False sharing,造成Cache Miss,结构体按Cache Line对齐
1 |
- 常量优化
常量相关的运算的编译阶段完成。比如C++11引入了constexp,比如可以使用GCC的__builtin_constant_p来判断值是否常量,然后对常量进行编译时得出结果。举例网络序主机序转换
1 |
|
其中rte_constant_bswap32的实现
1 |
|
5)使用CPU指令
现代CPU提供很多指令可直接完成常见功能,比如大小端转换,x86有bswap指令直接支持了。
1 | static inline uint64_t rte_arch_bswap64(uint64_t _x) |
这个实现,也是GLIBC的实现,先常量优化、CPU指令优化、最后才用裸代码实现。毕竟都是顶端程序员,对语言、编译器,对实现的追求不一样,所以造轮子前一定要先了解好轮子。
Google开源的cpu_features可以获取当前CPU支持什么特性,从而对特定CPU进行执行优化。高性能编程永无止境,对硬件、内核、编译器、开发语言的理解要深入且与时俱进。
DPDK 对比
DPDK still uses a small kernel module
with some drivers, but it does not contain driver logic and
is only used during initialization.
The downside is the poor
integration with the kernel, DPDK’s KNI (kernel network
interface) needs to copy packets to pass them to the kernel
unlike XDP or netmap which can just pass a pointer.
Other
advantages of DPDK are its support in the industry, mature
code base, and large community.DPDK supports virtually
all NICs commonly found in servers
netmap
a standard component in FreeBSD and also available
on Linux) offers interfaces to pass packets between the
kernel network stack and a user space app, it can even make
use of the kernel’s TCP/IP stack with StackMap
-
需要驱动支持,需要网卡厂商认可方案
-
依赖中断通知机制,未完全解决瓶颈
-
像是系统调用,实现用户态收发包,功能原始,没有网络开发框架,社区不完善